前几天在搭建hadoop集群的过程中遇到了很多问题,现在整合一下其他人的搭建过程,较为详细的讲解一下搭建的过程和需要实际修改的地方
ps:搭建hadoop集群最少需要三台机器,因为这点网上很少直接说明,因为这个的原因导致我集群一直无法启动
修改ip地址(三台机器)
#/ifcfg-ens33是网卡,具体是什么名字自行修改
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#修改以下内容
BOOTPROTO=static #设置静态获取ip
ONBOOT=yes
IPADDR=192.168.20.200 #IP地址,推荐分别设置为20.200,20.201,20.202
NETMASK=255.255.255.0
GATEWAY=192.168.20.2 #网关
DNS1=114.114.114.114
DNS2=8.8.8.8
分别修改主机名(三台机器)
#第一台机器
hostnamectl set-hostname master
#第二台机器
hostnamectl set-hostname clone1
#第三台机器
hostnamectl set-hostname clone2
配置域名解析(三台机器)
vi /etc/hosts
#添加
192.168.20.200 master
192.168.20.201 clone1
192.168.20.202 clone2
#三台做完后分别测试是否相互通信
ping -c 1 master;ping -c 1 clone1;ping -c 1 clone2
配置免密登入(三台机器)
ssh-keygen -t rsa
#三下回车
ssh-copy-id master
ssh-copy-id clone1
ssh-copy-id clone2
#测试免密登入,不用输入密码代表成功
ssh master
ssh clone1
ssh clone2
关闭防火墙和selinux
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
[root@master ~]# vi /etc/selinux/config
#关闭selinux
SELINUX=disabled
#通过xftp上传jdk和hadoop压缩包
#重启
[root@master ~]# reboot
ps: 此时可以拍摄快照
安装jdk和hadoop(第一台机器)
#jdk和hadoop版本不同的话需要自行修改
#确保jkd安装在/usr/local/ hadoop安装在/opt/hadoop/
[root@master opt]# tar -zxvf jdk-8u421-linux-x64.tar.gz -C /usr/local/
[root@master opt]# mkdir /opt/hadoop
[root@master opt]# tar -zxvf hadoop-2.7.1.tar.gz -C /opt/hadoop
[root@master opt]# vi /etc/profile
#在最后添加
#可以ls /usr/local看jdk名字,如果不同后续配置也需要修改,hadoop同理
export JAVA_HOME=/usr/local/jdk1.8.0_421
export PATH=$PATH:$JAVA_HOME/bin
# HADOOP_HOME
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
[root@master ~]# source /etc/profile
#以下没问题代表环境配置成功
[root@master opt]# java -version
java version "1.8.0_421"
Java(TM) SE Runtime Environment (build 1.8.0_421-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.421-b09, mixed mode)
[root@master opt]# hadoop version
Hadoop 2.7.1
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a
Compiled by jenkins on 2015-06-29T06:04Z
Compiled with protoc 2.5.0
From source with checksum fc0a1a23fc1868e4d5ee7fa2b28a58a
This command was run using /opt/hadoop/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1.jar
[root@master opt]# cd /opt/hadoop/hadoop-2.7.1/etc/hadoop/
[root@master hadoop]# ls
capacity-scheduler.xml hadoop-metrics2.properties httpfs-signature.secret log4j.properties ssl-client.xml.example
configuration.xsl hadoop-metrics.properties httpfs-site.xml mapred-env.cmd ssl-server.xml.example
container-executor.cfg hadoop-policy.xml kms-acls.xml mapred-env.sh yarn-env.cmd
core-site.xml hdfs-site.xml kms-env.sh mapred-queues.xml.template yarn-env.sh
hadoop-env.cmd httpfs-env.sh kms-log4j.properties mapred-site.xml yarn-site.xml
hadoop-env.sh httpfs-log4j.properties kms-site.xml slaves
#修改配置文件
[root@master hadoop]# vi hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_421
[root@master hadoop]# vi yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_421
#后续修改在每个文件的
<configuration>
</configuration>
中间插入内容
#master是第一台主机名,若不是master自行修改,端口同理,确保未被占用
[root@master hadoop]# vi core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
[root@master hadoop]# vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/dfs/data</value>
</property>
[root@master hadoop]# vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
[root@master hadoop]# vi yarn-site.xml
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
[root@master hadoop]# vi slaves
#hadoop3.X是叫workes
#添加另外两台主机名
clone1
clone2
修改好配置文件后再查看一下hadoop version(第一台机器)
[root@master ~]# java -version;hadoop version
java version "1.8.0_421"
Java(TM) SE Runtime Environment (build 1.8.0_421-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.421-b09, mixed mode)
Hadoop 2.7.1
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a
Compiled by jenkins on 2015-06-29T06:04Z
Compiled with protoc 2.5.0
From source with checksum fc0a1a23fc1868e4d5ee7fa2b28a58a
This command was run using /opt/hadoop/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1.jar
[root@master ~]# scp -rp /opt/hadoop/ root@clone1:/opt/
[root@master ~]# scp -rp /opt/hadoop/ root@clone2:/opt/
[root@master ~]# scp -rp /usr/local/jdk1.8.0_421 root@clone1:/usr/local/
[root@master ~]# scp -rp /usr/local/jdk1.8.0_421 root@clone2:/usr/local/
[root@master ~]# scp -rp /etc/profile root@clone1:/etc/profile
[root@master ~]# scp -rp /etc/profile root@clone2:/etc/profile
加载环境变量并验证(其他两台机器)
[root@clone2 ~]# source /etc/profile
[root@clone2 ~]# java -version;hadoop version
java version "1.8.0_421"
Java(TM) SE Runtime Environment (build 1.8.0_421-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.421-b09, mixed mode)
Hadoop 2.7.1
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a
Compiled by jenkins on 2015-06-29T06:04Z
Compiled with protoc 2.5.0
From source with checksum fc0a1a23fc1868e4d5ee7fa2b28a58a
This command was run using /opt/hadoop/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1.jar
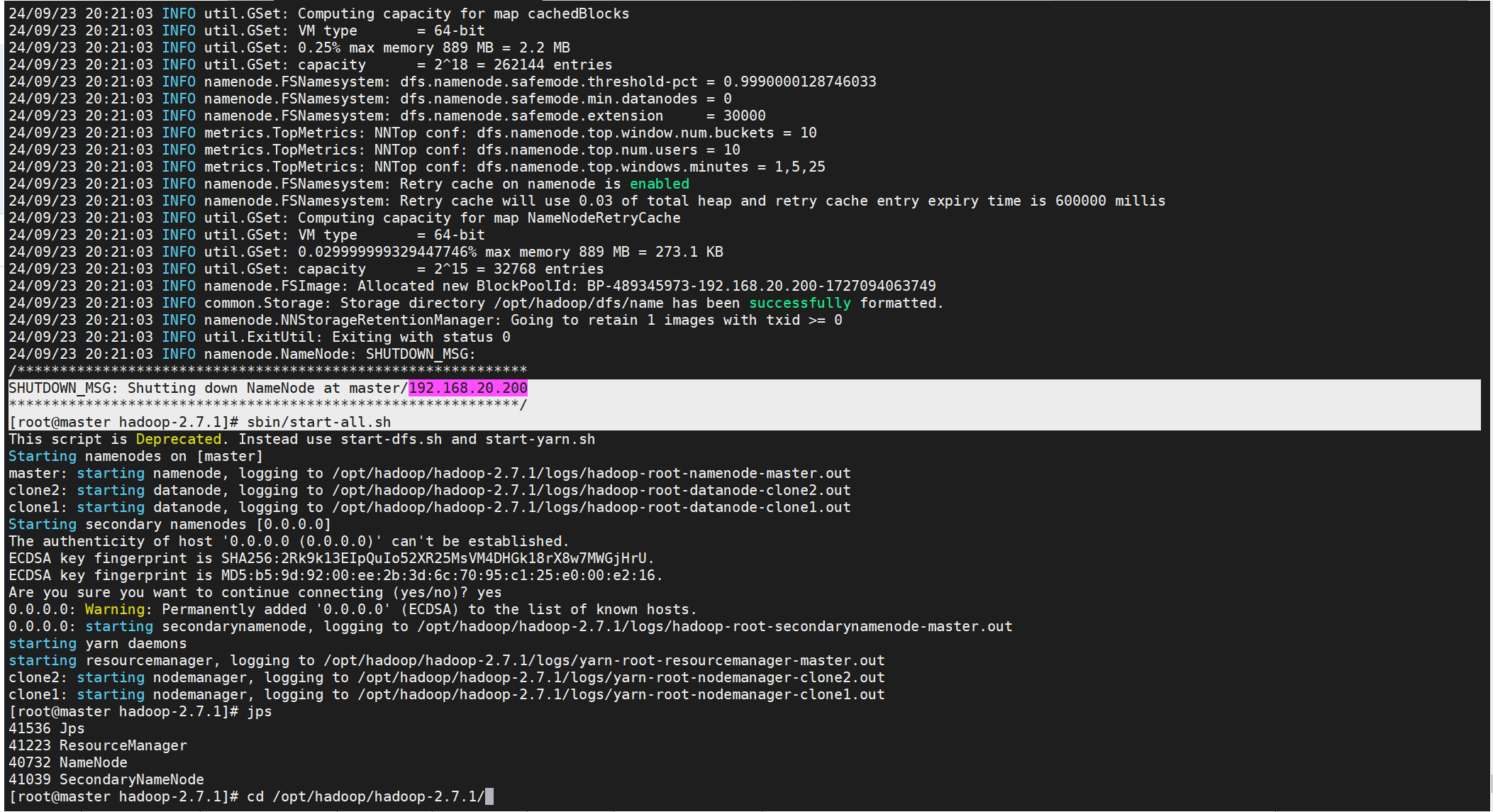
集群操作(第一台)
#初始化集群
[root@master hadoop-2.7.1]# cd /opt/hadoop/hadoop-2.7.1/
[root@master hadoop-2.7.1]# bin/hdfs namenode -format
···
#群起
[root@master hadoop-2.7.1]# sbin/start-all.sh
···
[root@master hadoop-2.7.1]# jps
41536 Jps
41223 ResourceManager
40732 NameNode
41039 SecondaryNameNode
出现次页面代表成功
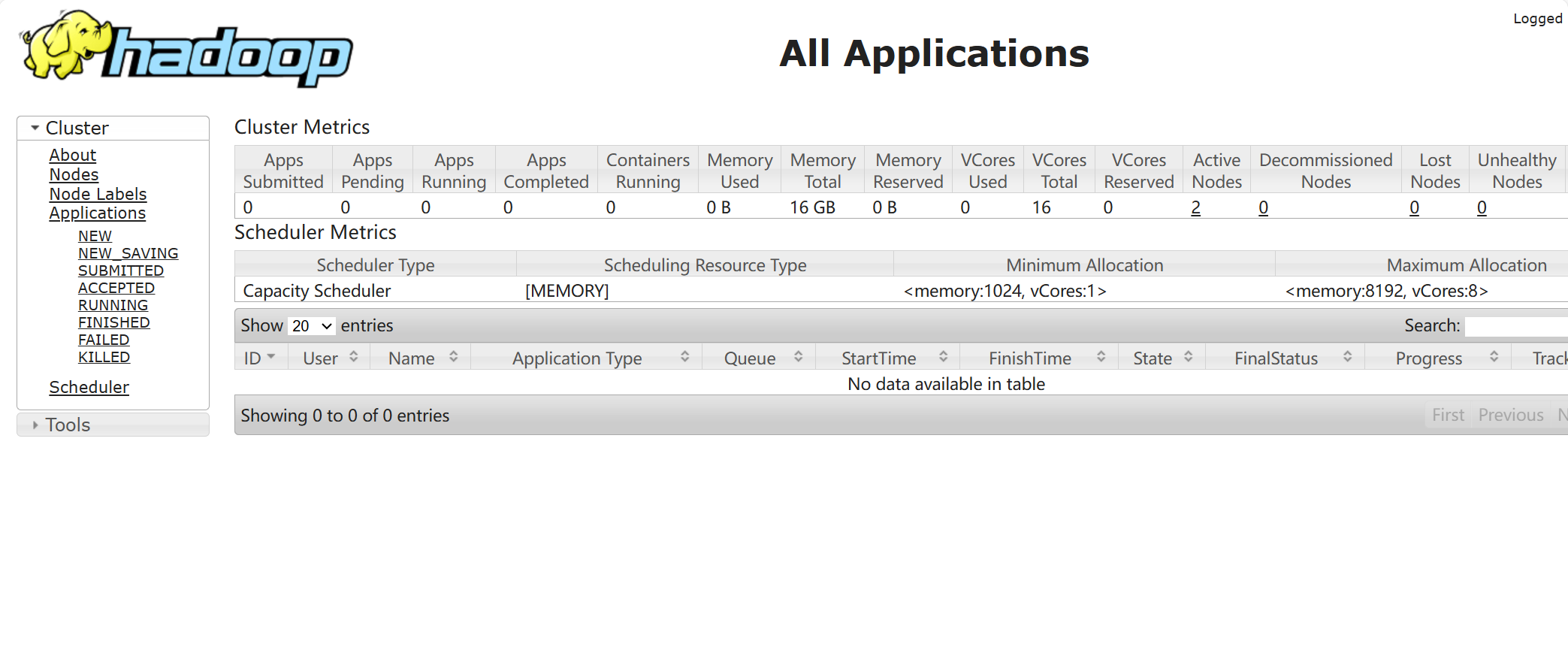
测试访问
在windows浏览器打开http://192.168.20.200:8088
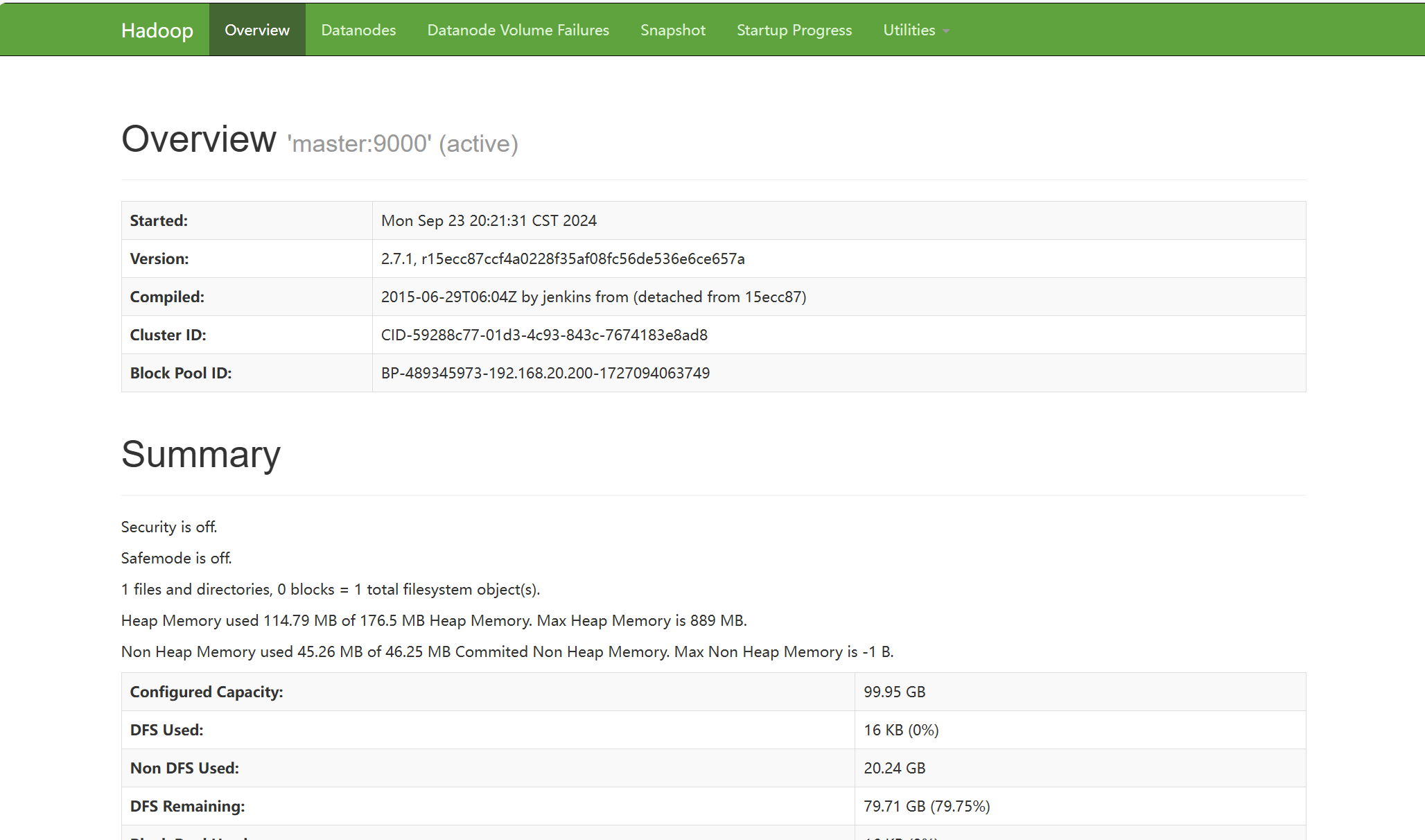
在windows浏览器打开http://192.168.20.200:50070
至此hadoop集群搭建完毕
作于2024年09月23日